


Looking for more? Get an updated, detailed post on my workflow at Organize and Write Your Next Novel with Obsidian.
Last updated: August 5, 2025
Jump over to my Linking Your Thinking session to see some of this in action.
Introduction My Journey to Obsidian
As a prolific author, I am able to test and tweak my methods to come up with my own workflow and best practices more quickly than most.
I used Scrivener for drafting and formatting books for about seven years. That workflow involved generating a docx file which I then manually tweaked with drop caps and other formatting features I could not accomplish directly within Scrivener, then using that file to create the other sizes/bindings that I needed. Then, of course, save them as pdf files for upload to my distributors. If I had changes to make to a book, I had to change the three or more docx files individually, as well as the Scrivener file which I still used to generate the epub and mobi versions. It was quite intensive. I was also running into problems with files becoming corrupted, taking huge lengths of time to open/close, and not converting properly from Scrivener version 2.0 to version 3.0.
I finally broke down and purchased Vellum in the summer of 2020, and at that point, began to rejig my workflow to eliminate Scrivener. (I have not completely eliminated it, as I still use it as a tool for formatting large print, but I no longer write in it, I just import a Vellum docx export file for that one task.)
I made a few attempts to use docx or odt files for my first draft before I landed on using Markdown files (one per chapter) for drafting, then compiling the Markdown files for my editor, and importing the finished file into Vellum for formatting and publishing. Now when I have changes to make, I only need to make them in Vellum, not in half a dozen different files, and I can produce my ebooks and print interiors with just a few clicks.
Initially, I was using Notebooks App to create the Markdown files and compile them, and have since made the shift to doing it all in Obsidian, using the Longform plugin. In August 2025, I have written over 70 books in Markdown, so I have had many iterations to tweak and refine the process discussed in this article.
Tip: If you are moving a project from Notebooks to the Longform plugin, you need to do one tweak first. Notebooks creates a plist file for each of your MD files, which contains various internal information about that file. In the latest version of Longform, you can tell it to ignore plist files.
Why Markdown?
Markdown files are plain text, with a few added characters or symbols used to format it for conversation to HTML or other formats. Being plain text files, they are very small and not likely to become corrupted. Writing one scene or one chapter per file also keeps them very small and can be opened in an instant. Since they are written in plain text, they can be edited with any text processor or word processor on any platform and are future-proof. Plain text will never become obsolete.
What is outlined below is what works best for me at this time. While I am tweaking it over time, especially as Obsidian adds new features, it is a solid process. A different process or set of tools may work better for you, so take what you will and don’t worry about the rest.
Versioning and file backup
Always back up your work! I use Dropbox to sync all of my data files across all of my devices, and the license that I pay for includes versioning, so I can roll any file back at any time if it becomes corrupted, overwritten, or something else disastrous happens, like a hard drive failure. I also use Mac OS Time Machine backups to four different hard drives so that I always have additional copies which can also be rolled back. And when I am actively drafting a new book, I also compile and save a backup every few days.
My file folder structure for a novel
- Writing
- My books
- Series folder (Obsidian vault)
- Novel folder (Longform project folder)
- archived (old drafts/versions of anything)
- backup (compiled backups of book made every few days)
-
- Drafts (Longform project folder)
- draft 1 … 2 … 3 …
- Editor or compiling notes (tasks about things I need to look at/write/review later, formatting, things to bring to the attention of my editor)
- graphics (covers, promotional graphics, ads, etc.)
- marketing metadata (back cover description, product listing, tags, tropes, comps, etc.)
- prep – preplanning – snowflake, outline, character sketches, blurbs, etc.
- published (Vellum output folder for this novel)
- Research and Notes
- Drafts (Longform project folder)
- templates (character notes, snowflake template, todo query template)
- Series wiki (linked “series Bible”)
- Novel folder (Longform project folder)
- Series folder (Obsidian vault)
- My books
Writing in Markdown
Writing your manuscript in plain text is pretty simple and I assume if you are reading this article you have a basic understanding of Markdown. (ie. double-returns between paragraphs, no tab indent, use *asterisks* for italics.)
I am not going to give a tutorial in using Longform or any of the other plugins mentioned in this article. You can find that documentation elsewhere. Here is one comprehensive guide.
Best practices
These are my “best practices” for drafting a book using Markdown files for eventual use in Vellum. They may or may not work for you, but will maybe give you a starting point for your own system.
File names
I write one chapter per Markdown file. It may consist of 1-3 scenes. I like to use descriptive file name for the chapter so that I can quickly find what I am looking for and jump from one scene to another. They are numbered so that they can be sorted sequentially in any file viewer or editor. (If I look at them in the Mac Finder or on my iphone dropbox app, they are in order.) Some apps will let you manually arrange the chapters in the order you want them in, so you can drag them around until it suits you. I would suggest that once you are pretty sure of the order, you number them. I generally write in sequence, but sometimes I’ll write three or four chapters without a number, just in case I decide I want to add or move around a scene, and then number them once the sequence is solidified. Of course, you can always move things around and renumber again later. I would like to see the Longform app add auto-numbering at some point. Having chapters numbered sequentially in Obsidian means that you can sort them in order in Mac Finder, Windows Explorer, or any other file browser.
When I import into Vellum, I clear the title and just use let Vellum autonumber the chapters. If you use named chapters in your final copy, then use your chapter names as your file names.
Tip: If you find that Longform has reordered your scenes (which it seems to do sometimes when I switch between computers), it can be pretty time-consuming to drag them back into the right order again, especially with fifty or more chapters. If you have your files numbered and open the Longform index.md file and sort the chapters there, they will automatically be reodered in Longform. I use PopClip on the Mac and it has a sort extension, so I can just highlight the block of scenes and tell it to sort and I’m done. I use two-digit numbers so that 01-09 sort before 10. —I haven’t had this issue since the last version of Longform was released, but do occasionally find that Longform forgets my project and it needs to be redefined.
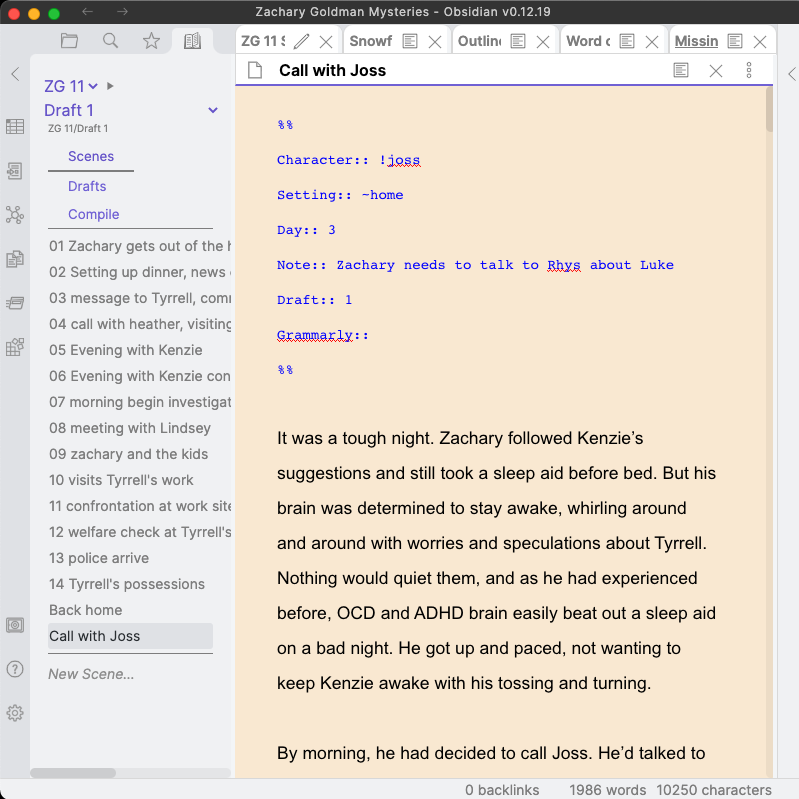
Front matter (YAML or Properties)
I put queryable metadata (called YAML or front matter) at the top of each MD file to track certain informaiton in each chapter. There are a number of different ways to do this, depending on which editor you want to use as your main Markdown editor. Obsidian has added Properties, which makes the front matter/metadata easier to manage. The Properties core plugin that gives you a nice editable sidebar view for your properties, which is nice if you want to make a change to your properties when you are down at the bottom of the file without scrolling back up to the top.

The information normally included in a YAML header is things like title, author, and date (examples). Some apps or plugins (such as Obsidian Dataview) may make use of other variables to be included in the YAML header.
The latest version of Longform gives you the option of removing your YAML front matter when compiling.
Metadata I Use
You can use the YAML header/Properties to add whatever tags or information you want to track, search, or filter. My metadata may look something like this.

I precede character names with ; and setting names with ~ so that I can also search/filter them quickly from any file explorer. Why would I not just search Malachi instead of ;Malachi? Because I don’t want to bring up every scene that Malachi is mentioned in, only the ones where he is a main character in the scene.
I only use POV in books that have multiple points of view. If there is only one POV in the book, I don’t need to track it. Similarly, if every scene in the book uses Joe Blow’s POV, then I don’t include ;Joe in the list of characters. He would be listed for every single scene and there’s never any need to filter on him.
Day helps me to keep track of day of the week or month, length of time between scenes, etc. so I don’t have to go back and count days later.
Note is anything that I need to remember for later or to add to the series wiki.
Draft is the draft number
Grammarly indicates whether I have run the scene through Grammarly. Yes—you can copy and paste Markdown text into Grammarly and it will not screw up the paragraph spacing, italics, etc. like many formats do. You can check the file and paste the results back into your Markdown file, and everything will still be properly formatted.
You can also use the new Grammarly desktop app to check spelling and grammar within an Obsidian file rather than having to copy and paste in to the editor. It is still pretty flaky, so I’ve gone back to copy and paste into the web app.
Critique means that the chapter has been critiqued and TTS that I have proofed it using Text to Speech.
As well as letting me search or filter by these variables in any file browser, I can also use the Obsidian Dataview plugin to produce a tabulated summary, like this:
Dataview query

Produces these results



This functionality will probably be replaced by Bases, currently in beta testing in Obsidian.
Other special formatting considerations
H1 Headers for chapters
H1 headers are automatically recognized by Vellum as chapter titles. If you use H1 headers, you will never fail in your chapters dividing in the correct place and retaining their names when imported into Vellum. Other methods will sometimes fail to divide every chapter correctly.
Notebooks has the option to make the first line of a file an H1 header (and by default synchronizes the first line of the file and the file name.) The Obsidian Longform plugin lets you add your Scene name as an H1 header in the compiling process.
If you are using other tools, create an H1 header by typing # followed by a space and your header.
# HeaderMarking scene breaks
If you are importing into Vellum, then you want all of your scene breaks to be properly marked. Trust me, you don’t want to have to input all of your scene breaks by hand after the file has been imported!
If you use *** or --- to mark your scene breaks, then they will be converted to a horizontal line <hr> when you convert to docx. And horizontal lines are not recognized by Vellum as scene breaks.
If you use +++ to mark your scene breaks (you don’t need to center it), it will not be converted to a horizontal line when you convert to docx. It will stay as a +++. And +++ is recognized as as scene break by Vellum.
My Obsidian Longform plugin formatting
You can format your editing and preview screens in Obsidian using CSS formatting that only applies to Longform project files.
Update: I no longer do much CSS formatting, other than changing the colour of the YAML header. But I’ll keep this here just for reference if you want it. I thought that when I went back to read my books, it would be nice to read in the reading view (preview screen) shown below, but I actually never use that view!
My edit screen:

My preview screen:

My sample CSS
/* Font for the markdown source (edit) view */
.longform-leaf .cm-s-obsidian
{
font-family: Atkinson Hyperlegible;
font-size: 1.1em;
line-height: 2em;
}
.longform-leaf .cm-hmd-frontmatter
{
font-family: monospace;
font-size: .8em;
line-height: 1em;
color: firebrick;
}
.longform-leaf .cm-comment
{
font-family: monospace;
font-size: .8em;
line-height: 1em;
}
.longform-leaf .cm-header-1
{
font-family: Garamond;
font-size: 1.5em;
line-height: 2em;
font-weight: bold !important;
}
.longform-leaf .cm-header-2
{
font-family: Garamond;
font-size: 1.2em;
line-height: 1.5em;
}
.longform-leaf .cm-header-4
{
font-family: Garamond;
font-size: 1em;
line-height: 1em;
font-weight: normal;
}
/* Font for the markdown preview view */
.longform-leaf .markdown-preview-view {
font-family: Garamond;
font-size: 1.2em;
text-indent: 1em;
text-align: justify;
}
.longform-leaf ul {
list-style-position: outside;
}
.longform-leaf ol {
list-style-position: outside;
}
.longform-leaf li {
padding-left: 0em;
padding-bottom: 2 em;
}
.longform-leaf h1 {
font-family: Garamond;
font-size: 2em;
text-indent: 0em;
margin-top: 1em;
}
.longform-leaf p {
margin-bottom: -15px;
line-height: 1.3em;
}
.longform-leaf .admonition-content p {
margin-bottom: 0px;
line-height: 1.3em;
text-indent: 0em;
}
.longform-leaf div.callout p {
margin-bottom: 0px;
line-height: 1.3em;
text-indent: 0em;
}
.longform-leaf .markdown-preview-sizer .markdown-preview-section {
font-family: Garamond;
font-size: .8em;
text-indent: 0em;
text-align: justify;
}
.longform-leaf {
--background-primary: antiquewhite;
--background-primary-alt: white;
--background-secondary: white;
--background-secondary-alt: white;
--text-selection: #aaa;
--text-normal: black;
--text-faint: blue;
color: black;
}
.longform-leaf .suggestion-item.is-selected {
background-color: var(--text-accent);
}
.longform-leaf .markdown-preview-view blockquote {
border-color: darkgrey;
font-size: 95%;
text-align: left;
hyphens: auto;
word-break: keep-all;
color: black; # you need to define
font-color: #aacdbe;
line-height: 1.3;
padding: 10px 2% 10px 2%;
margin-top: 15pt;
margin-bottom: 15pt;
}
/* Remove bullets from dataview table */
.dataview-result-list-li {
list-style-type: none;
padding: 0 !important;
indent: 0em;
}
.list-view-ul {
list-style-type: none;
padding: 0 !important;
indent: 0em;
}
.callout[data-callout-metadata="x"] .callout-title {
display: none;
}
Old Workspace
My layout when planning is pretty fluid. I may have a couple of side-by-side panes/tab groups, along with a separate window showcasing the mind map or kanban board for the book.
Here is my one workspace layout I have used while drafting or editing that Scrivener users may like.

Working clockwise around the workspace:
Top left – Explorer
The Obsidian Explorer, search, and Longform plugin panels. I switch between them as I like. Usually set for Obsidian Explorer.
Central – Editor
Pretty self-explanatory. The scene or scenes that I have open in the editor at the moment. Obsidian now allows these to be set up as tabs.
Top right – Unlinked Mentions
As I mention people, places, magical races, etc. that I have series wiki entries for, research articles, etc., they will pop up in the unlinked mentions panel. I would like to be able to just click to jump to a reference, but at the moment, you have to click to link, and then click to follow the link. You can either remove the link afterward or leave it in there and have Longform plugin remove it from the exported manuscript. I’d love to see more unlinked mentions functionality in Obsidian. To use this functionality, you need to have the Core plugin Outgoing links turned on.
Bottom right – Starred
The panel shown is the Starred panel, which has been replaced in Obsidian with Bookmarks. With Bookmarks, I can quickly jump to my to do list for the book, my Outline, scenes summary, the series wiki, open my Excel word count spreadsheet to record today’s count, etc. Cmd-click on a file to open it into a new tab.
Bottom left – Metadata
My previous method of viewing the metadata in the sidebar has been replaced with Obsidian Properties.
New Workspace

Left Panel
File Explorer, Search, Bookmarks, and Longform scenes
Middle Panel
Editor
Right Panel
Most often, the Properties View.
Tasks within a project
I normally manage all of my projects and tasks with Todoist, and any tasks that I note in Obsidian, I migrate to Todoist. However, for book drafts, I keep the internal editing tasks inside Obsidian. I may have “Review ACB 20 tasks/edits” in Todoist, but the tasks I’ve made while drafting or editing live within Obsidian, embedded within the scene they apply to.
I have a Todo document for each draft, something like this:

The top section is tasks that apply to the whole book generally. Things I need to check for consistency or change after I am finished the current draft. I try to always keep things moving forward as I am writing the first draft and don’t go back to do corrections until that draft is completed.
The middle section is a query for unchecked tasks in each scene. You see the scene name and then the checkboxes found within that scene.
The bottom section is things I need to do before sending the final draft to my editor, notes of things to discuss with my editor, etc. and things to do when I get it back, before or after importing into Vellum as I get it ready for publication. The initial tasks are part of my Todo template and I add to them as I write.
I may have an audio section as well, which is words that need to be checked for proper pronunciation when I convert them to an autonarrated audiobook.
Other settings/plugins that I find helpful drafting novels in Obsidian
As well as the Longform and Pandoc plugins (below), I also find these to be useful when drafting novels.
Dataview Plugin
Needed to produce the data summaries you see above with my metadata and word count.
This will probably be replaced by Obsidian’s new Bases plugin, when it comes out of beta.
Smart Typography Plugin
I want curly quotes and apostrophes. I want my ellipses converted. Other than that, I turn the rest off.
I recommend that if you use Smart Typography, you turn off “auto pair brackets” in your editor preferences. Otherwise things can get a little wonky.
Templates Plugin (Core)
I use templates for my character notes and my snowflake planning. I could also use them to automatically insert my metadata template. Alternatively, you could use TextExpander or another utility for this.
Bookmarks Plugin (Core)
I like to bookmark certain reference documents, such as my outline, word count dashboard, etc.
Wikilinks (Preferences)
I use Wikilinks to set up my series wiki (series Bible).
Excalidraw
I am now using the core plugin Canvas rather than Excalidraw for storyboarding, unless it is a really complex intertwining of plotlines, like the one shown below.

Kanban
Kanban is another way to visualize your plot, manage tasks, etc. It is easy to drag and reorder both the lists and cards. You can view it as either a Kanban or as a markdown file (headers with tasks).


Text Generator
Useful for summarizing, critiquing, generating names or titles, social media posts, ad copy, preliminary research questions, etc.
Note Refactor
Sometimes I do sprints in OhWrite. While it doesn’t say so anywhere on the site, you can use Markdown within the OhWrite editor. So I mark my chapter breaks with ## for an H2 heading and insert my YAML header right in OhWrite, and then paste the whole thing into a note in Obsidian when I’m done. Using the Note Refactor plugin, I can instantly split this file into the multiple chapters without copying and pasting each manually.
Compiling and Converting to final format
If you are drafting one scene or chapter per file, as you do with the Longform plugin, then you are going to need tools that (a) combine those chapters into one long file and (b) convert that compiled file into docx format for your editor and/or for import into Vellum and/or to convert into epub and pdf for publication. I am going to focus on getting from Markdown to Vellum here, you will need to experiment and adapt for other formats.
Obsidian Longform Plugin
You can compile all files in the draft folder of a Longform project by going to the Longform panel compile tab and clicking compile. Prepend the title to the scene as shown below to add it as an H1 header. Longform has steps to let you remove comments, front matter, strikethrough text, links, etc. before compiling so that you have a clean copy to give to your editor.

Converting to your final file format with Pandoc
The Obsidian Longform Plugin will compile all of the Scenes into one long MD (markdown) file.
To convert from MD to docx, you will want to use Pandoc. Pandoc is a command line file converter that lets you convert from one file format to another in Terminal. But don’t panic. If you are using Obsidian, install the Pandoc Plugin. (If you are using another Markdown editor, you will need to see what the options are available, learn Pandoc command line prompts, or use an online tool such as StackEdit to convert the file from MD to docx. Katrina commented below that she uses Ulysses to compile and convert her manuscript.)
To convert using Pandoc plugin in Obsidian: navigate to the compiled MD file and click on it. Pull up the command palette (cmd-p) and type docx. If you have Pandoc set up properly, you should see “Pandoc Plugin: Export as docx” Select this option to convert your MD file to a docx file.
This new docx file can be imported into Vellum and all Chapter and Scene breaks will be properly converted. (Of course, you may want to send it to your editor first, and the import the finalized file into Vellum.) If you don’t want your chapters to have names, you can select all of your chapters on the left navigation panel and clear the titles. Then they will just show up as Chapter 1, Chapter 2, etc.
If you have sections that will need to be converted to alignment blocks or other special formatting, I suggest that you use a symbol combination to mark each of those sections while working in Markdown, and then search for that combination in the Vellum file and format it accordingly, as they may not look the way you want/expect when they are converted.
eg. use “999 alignment block” and search for 999 in the text in Vellum after importing.
Vellum also does not import graphics embedded in your docx file. You will need to insert them manually.
Other formats
You can use Pandoc to create pdf files, epub files, etc. directly and not use Vellum or another formatting program. I have not experimented with this for novels. I have used Pandoc to create very nice formatted pdf files for printed newsletters (for people who want print copies rather than emails), but that is a topic for a separate article. It would take a little bit of work to get exactly the format you want for a book, but it would certainly be possible. Pandoc even has codes for running headers and footers. But I am happy with Vellum and it is so easy to use!

Looking for a comprehensive book on writing your book in Obsidian?
The Writer’s Guide to Obsidian, A Practical System to Organize, Outline, Draft, and Edit Your Next Book in Markdown is coming soon!
You can preorder now.
More Articles on Obsidian

Obsidian for Writers
Organize and Write Your Next Novel with Obsidian

Annotations
Elevate Your Writing Process: Using Callouts in Obsidian
Writing a Novel with Obsidian
Writing 70+ novels in Obsidian
FAQ: Writing a Novel in Markdown
- What is Markdown and why is it good for writing novels?
Markdown is a lightweight markup language that lets you format text using plain characters. It’s ideal for novel writing because it keeps your content distraction-free, easy to back up, and compatible with many writing and publishing tools. Shorter, lighter content is less likely to get corrupted than the bloated files in other programs. - Can I write a complete book using only Markdown?
Yes, you can write an entire novel in Markdown. Many authors use tools like Obsidian, Typora, Ulysses, or VS Code to draft, organize, and export their books from Markdown to various formats like DOCX, EPUB or PDF. - Which Markdown apps are best for fiction writers?
Popular Markdown apps for fiction writers include Obsidian (great for linking and organization), Typora (for WYSIWYG writing), and MarkText. Each offers a clean interface and powerful export features. - How do I organize my chapters and scenes in Markdown?
You can use folders, nested files, and headers (e.g.# Chapter 1,## Scene 1) to structure your manuscript. Tools like Obsidian also let you link between notes and use tags for easy navigation. - Can I export my Markdown novel to Word or PDF for publishing?
Yes, you can export your Markdown files to DOCX, PDF, EPUB, and more using tools like Pandoc, Marked 2, or built-in export features in your Markdown editor. - How do I handle formatting like italics, bold, and scene breaks in Markdown?
Use*italics*,**bold**, and***or---for scene breaks. These simple syntax elements are easy to learn and work across all Markdown platforms. - Is Markdown compatible with self-publishing platforms like Amazon KDP?
Yes, Markdown can be converted to EPUB, DOCX, or PDF for uploading to Amazon KDP and other platforms. With proper formatting and conversion tools, it’s easy to prepare your novel for publishing. - Does writing in Markdown help with writer’s block or productivity?
Many writers find Markdown’s simplicity reduces distractions and improves focus. The plain-text environment encourages flow and makes it easier to maintain momentum. - What are the disadvantages of writing a novel in Markdown?
While Markdown is flexible and minimalist, it may lack some of the visual tools of rich text editors. Advanced formatting, footnotes, and tables may require extra setup or external tools. Apps like Obsidian with endless customization options can tempting and distract writers from their #1 job—writing! - Can I collaborate with editors or beta readers using Markdown?
Yes, you can share Markdown files via GitHub, Obsidian Publish, Google Docs (converted), or export them to Word for tracked changes. Tools like HedgeDoc or HackMD also support real-time collaboration.









Thank you, very interesting insights on your workflow! As you are now using the canvas plugin for storyboarding, you may find the new plugin Canvas2Document useful. Canvas2Document lets you convert any obsidian canvas structure with all content, i.e. cards, notes, media from the 2-dimensional representation into the linear structure of a document. See https://github.com/slnsys/obsidian-canvas2document
I’ve recently had issues with Scrivener crashing on me, and your article made all the difference in my transition to Obsidian! Thank you so much.
A few remarks on plugin suggestions:
1. The Obsidian Pandoc plugin hasn’t been updated in over two years, and pandoc templates are causing it to crash. Fortunately, the Enhancing Export plugin is a worthy successor:
https://github.com/mokeyish/obsidian-enhancing-export
It’s perfect for basic exports, but the legwork required to export in standard manuscript format remains considerable. This git repo is a good starting point:
https://github.com/prosegrinder/pandoc-templates
2. The Kanban plugin also hasn’t been updated in a while, but every glitch I’ve encountered can be resolved by simply closing & reopening the note. Colored Tags is a useful plugin here to differentiate between types of tasks, story notes, etc.
3. On that note, for those who frequently use tags in Obsidian, Tag Wrangler is a must.
4. For those dealing with a lot of deadlines, the Tasks plugin paired with either Time Ruler or Tasks Calendar Wrapper may be a better option than Kanban.
5. Lastly, the Iconize app allows for icons to be added to File Explorer, which makes navigation much easier.
Thanks again!
Glad it helped! I haven’t had any issues with Pandoc or Kanban, but then I’m not doing anything very complicated with them, either. The heavy lifting for my formatting is done later in Vellum, after I get my ms back from my editor. Great suggestions for solutions and other plugins.
Hi,
Thank you for the article. This is super random but what is the theme you are using in obsidian?
I am actually just using the default theme for my writing vaults.
I think that… thanks a lot for sharing your insights 🙂
Really love this and wanna discuss more and dig in. Is there any possible there can I interview you on youtube? Here is my channel https://www.youtube.com/c/FredLai .
Thanks for this great article, which I found out about from someone on the Obsidian Discord community. I’ve been working on my books in Scrivener for a LONG time, but am thinking of switching to Obsidian. Your tips are so helpful for explaining options in how to put everything together at the end. I’ll end up having to convert everything to Microsoft Word format before sending to my editor.
Glad to help! And exporting from Scrivener to Markdown is not hard to do if you want to switch something that is in progress right now.
Interesting workflow. I’m still working on my first fiction project in Obsidian. I use a lot of the same workflow you have detailed but I don’t use the Longform plugin. I have a shared external folder between Obsidian and Ulysses for my book project. Once my work in Obsidian is done I can open the folder in Ulysses and run through additional formatting and editing changes, then export in multiple formats (including HTML). I hadn’t decided if I wanted to invest in Vellum or some other formatting app yet, but I have used basic Word files and uploaded those in the past for KDP. I just haven’t worked on anything for Print for a long time.
That’s great! I’ll add Ulysses into the article as another way to compile into a single book manuscript.
Pingback: PKM Weekly for January 10 2022 – Issue 001 – Curtis McHale
Very helpful explanation. One question, my editor works in Google Docs. Have you tried Pandoc for this? Now, I’m off to stare at my WIP and imagine the turmoil and wonder of converting it from Scrivener to markdown. Good excuse not to write, as always 🙂
Actually, converting from Scrivener to Markdown is super easy!
File > Export > Files…
Select Export text files as: MultiMarkdown (.md)
Under options, I select:
X Number exported files
X Append “.md” extension
X Convert rich text to MultiMarkdown
And you can upload docx into Google Docs.